趁着毕设初期,还能摸会儿🐟,了解波 Kafka。
Kafka 术语一览
Kafka,分布式消息引擎系统,主要功能是提供一套完备的消息发布与订阅解决方案。Kafka 也是一个分布式的、分区的、多副本的多订阅者,基于 Zookeeper 协调的分布式日志系统,可用于处理 Web 日志和消息服务。
Topic:主题,承载消息(Record)的逻辑容器,每条发布到 Kafka 集群的消息都归属于某一个 Topic,实际应用中,不同的 topic 对应着不同的业务;
Broker:Kafka 服务进程,一个 Kafka 集群由多个 Broker 服务进程组成,虽然多个 Broker 可在同一服务器上进行部署,但为了高可用,会将不同的 Broker 部署在不同的机器上;
Partition:分区,一组有序的消息序列,一个 Topic 可以有多个分区,同一 Topic 下的 Partition 可以分布在不同的 Broker 中。Producer 生产的每一条消息都会被放到一个 Partition 中,每条消息在 Partition 中的位置信息由一个 Offset(偏移量)数据表征。Kafka 通过偏移量(Offset)来保证消息在分区内的顺序性;
Leader:每个 Partition 下可以配置多个 Replica(副本),Replica 由一个 Leader 和多个 Follower 组成,Leader 负责当前 Partition 消息的读写;
Follower:用于同步 Leader 中的数据,数据冗余,Leader 失效时会从 Followers 中选取;
Producer:生产者即数据的发布者。Producer 将消息发送给 Kafka 对应的 Topic 中,Broker 接收到消息后,会将消息存储到 Partition 中;
Consumer:消费者,消费者可以消费多个 Topic 中的消息,一个 Topic 中的消息也可以被多个消费者消费;
Consumer Group:消费者组,每一个消费者都会归属于某一个消费者组,如果未指定,则取默认的 Group;
Consumer Offset:消费者位移,用于表示消费者的消费进度;
与 Kafka 相关的几个问题:
Broker 分布式部署
备份机制(Replacation),把相同的数据拷贝到多台机器上。即 Kafka Replica,Leader Replica 提供数据的读写操作,Follower Replica 负责同步数据。
Partition 机制,一个 Topic 划分为多个 Partition,防止单台 Broker 机器无法容纳太多的数据,Partition 机制与 Replica 机制联系紧密,每个 Partition 可以有多个 Replica(1 Leader + N Followers)。
Zookeeper 可为分布式系统提供分布式配置服务、同步服务和命名注册服务。
从前文可知,Kafka 的消息存储在 Topic 中,一个 Topic 又可以划分为多个 Partition,多 Partition 时,Kafka 只能保证 Partition 内的消息有序(Offset保证有序),如需保证 Topic 消息的有序,那么只能使用单个Partition了。如果仍要使用多个 Partition,消息的分区写入策略应选择按键(Key)保存。
通过 Go 体验一下 Kafka
环境搭建
既然只是玩一下,不如使用 Docker 搭建 Kafka 环境吧,“即用即焚”。
环境:Windows 10 Docker Desktop + WSL
这里通过 Docker-Compose 搭建个单机版的 kafka 集群,编排文件如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 version: '3.4' services: zoo1: container_name: zookeeper-one image: zookeeper:3.4.9 hostname: zoo1 ports: - "2181:2181" environment: ZOO_MY_ID: 1 ZOO_PORT: 2181 ZOO_SERVERS: server.1=zoo1:2888:3888 volumes: - ./zk-single-kafka-single/zoo1/data:/data - ./zk-single-kafka-single/zoo1/datalog:/datalog kafka1: container_name: kafka-one image: confluentinc/cp-kafka:5.3.1 hostname: kafka1 ports: - "9092:9092" environment: KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka1:19092,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181" KAFKA_BROKER_ID: 1 KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO" KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 volumes: - ./zk-single-kafka-single/kafka1/data:/var/lib/kafka/data depends_on: - zoo1
该编排文件来自:https://github.com/simplesteph/kafka-stack-docker-compose 的 zk-single-kafka-single.yml。使用 docker-compose up 启动容器。
编排文件中所使用到的镜像 confluentinc/cp-kafka:5.3.1 和 zookeeper:3.4.9 配置参考:
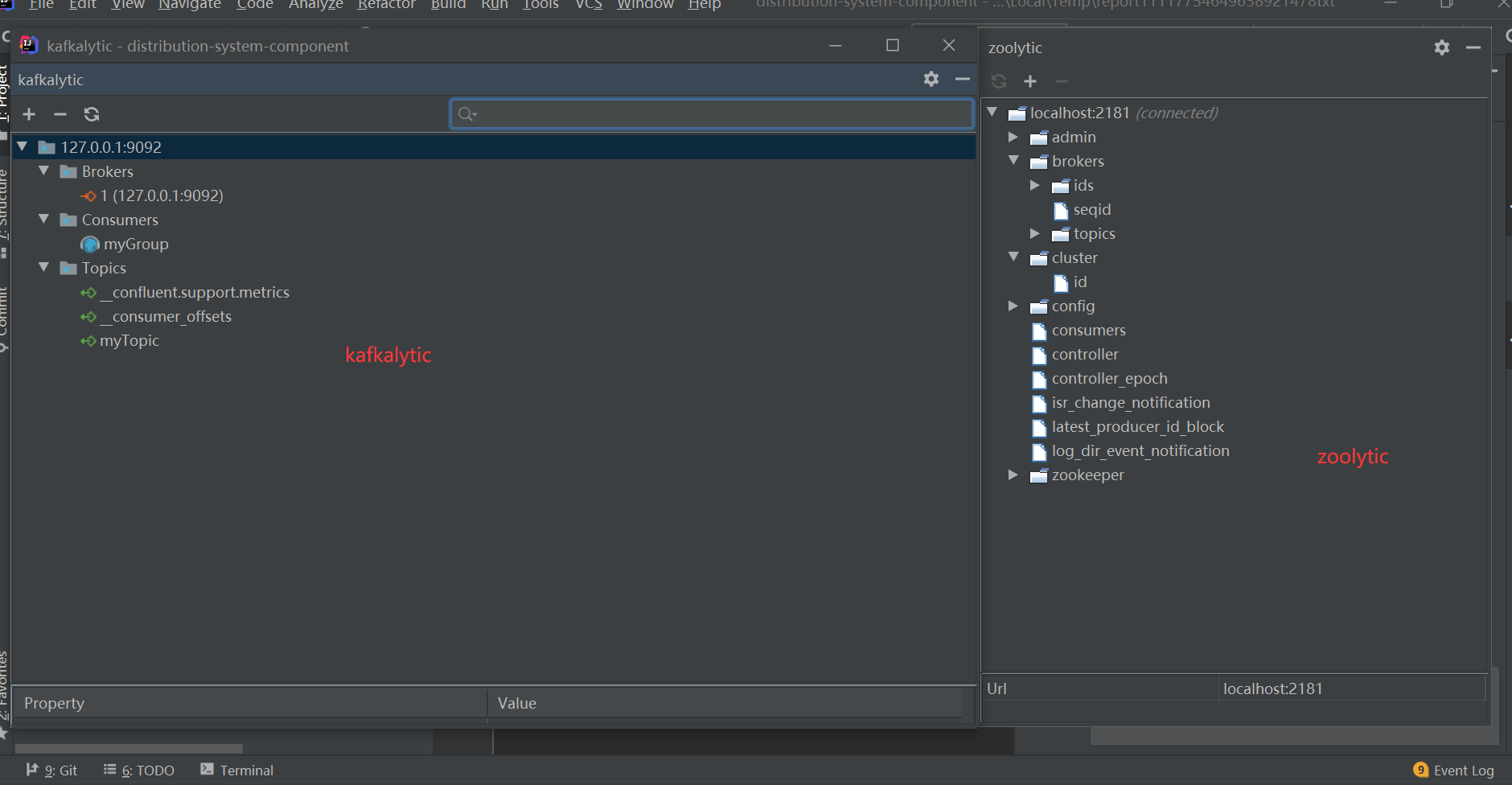
Kafka 和 Zookeeper 容器启动后,配合 IDEA 的两个插件 Kafkalytic 和 Zoolytic ,我们可以很方便的观察集群的情况:
Cluster Management
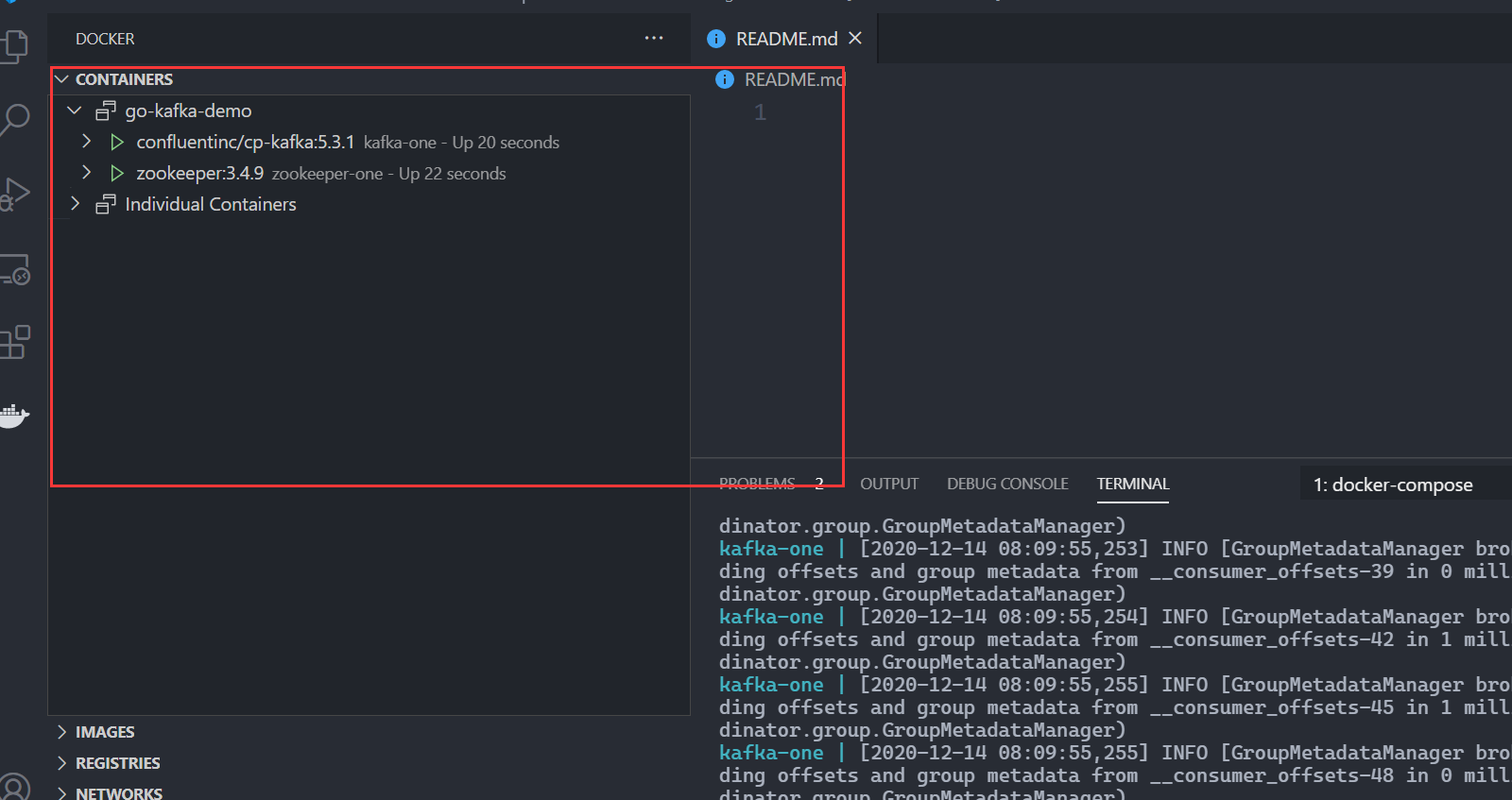
通过 vscode 插件我们可以方便的对启动的容器进行管理(日志追踪、shell attach等):
vscode docker plugin
通过 Kafka 自带的命令行工具可以查看 Topic:(先连接到 Kafka 容器:docker exec -it kafka-one bash)
1 2 3 4 5 root@kafka1:/# kafka-topics --describe --zookeeper zoo1:2181 Topic:__confluent.support.metrics PartitionCount:1 ReplicationFactor:1 Configs:retention.ms=31536000000 Topic: __confluent.support.metrics Partition: 0 Leader: 1 Replicas: 1 Isr: 1 Topic:__consumer_offsets PartitionCount:50 ReplicationFactor:1 Configs:s ......
使用 confluent-kafka-go 体验 Kafka
Go 中有两个比较有名的 Go Client,即 kafka-go 和 confluent-kafka-go 。我都不熟悉😂,但是前面编排时用到了 confluent 公司的 Kafka 镜像,所以这里选用 confluent-kafka-go 创建 Client。confluent-kafka-go 项目的 example 拿来即用。
1、创建 Go Module
1 2 3 4 mkdir go-kafka-demo cd go-kafka-demo go mod init github.com/yeshan333/go-kafka-demo go get -u github.com/confluentinc/confluent-kafka-go
2、创建 Consumer。这个 Consumer 订阅的 Topic 为 myTopic。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package mainimport ( "fmt" "github.com/confluentinc/confluent-kafka-go/kafka" ) func main () c, err := kafka.NewConsumer(&kafka.ConfigMap{ "bootstrap.servers" : "localhost" , "group.id" : "myGroup" , "auto.offset.reset" : "earliest" , }) if err != nil { panic (err) } c.SubscribeTopics([]string {"myTopic" , "^aRegex.*[Tt]opic" }, nil ) for { msg, err := c.ReadMessage(-1 ) if err == nil { fmt.Printf("Message on %s: %s\n" , msg.TopicPartition, string (msg.Value)) } else { fmt.Printf("Consumer error: %v (%v)\n" , err, msg) } } c.Close() }
3、创建 Producer。这个 Producer 向 myTopic Topic 发送了 7 条消息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package mainimport ( "fmt" "github.com/confluentinc/confluent-kafka-go/kafka" ) func main () p, err := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers" : "localhost" }) if err != nil { panic (err) } defer p.Close() go func () for e := range p.Events() { switch ev := e.(type ) { case *kafka.Message: if ev.TopicPartition.Error != nil { fmt.Printf("Delivery failed: %v\n" , ev.TopicPartition) } else { fmt.Printf("Delivered message to %v\n" , ev.TopicPartition) } } } }() topic := "myTopic" for _, word := range []string {"Welcome" , "to" , "the" , "Confluent" , "Kafka" , "Golang" , "client" } { p.Produce(&kafka.Message{ TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Value: []byte (word), }, nil ) } p.Flush(15 * 1000 ) }
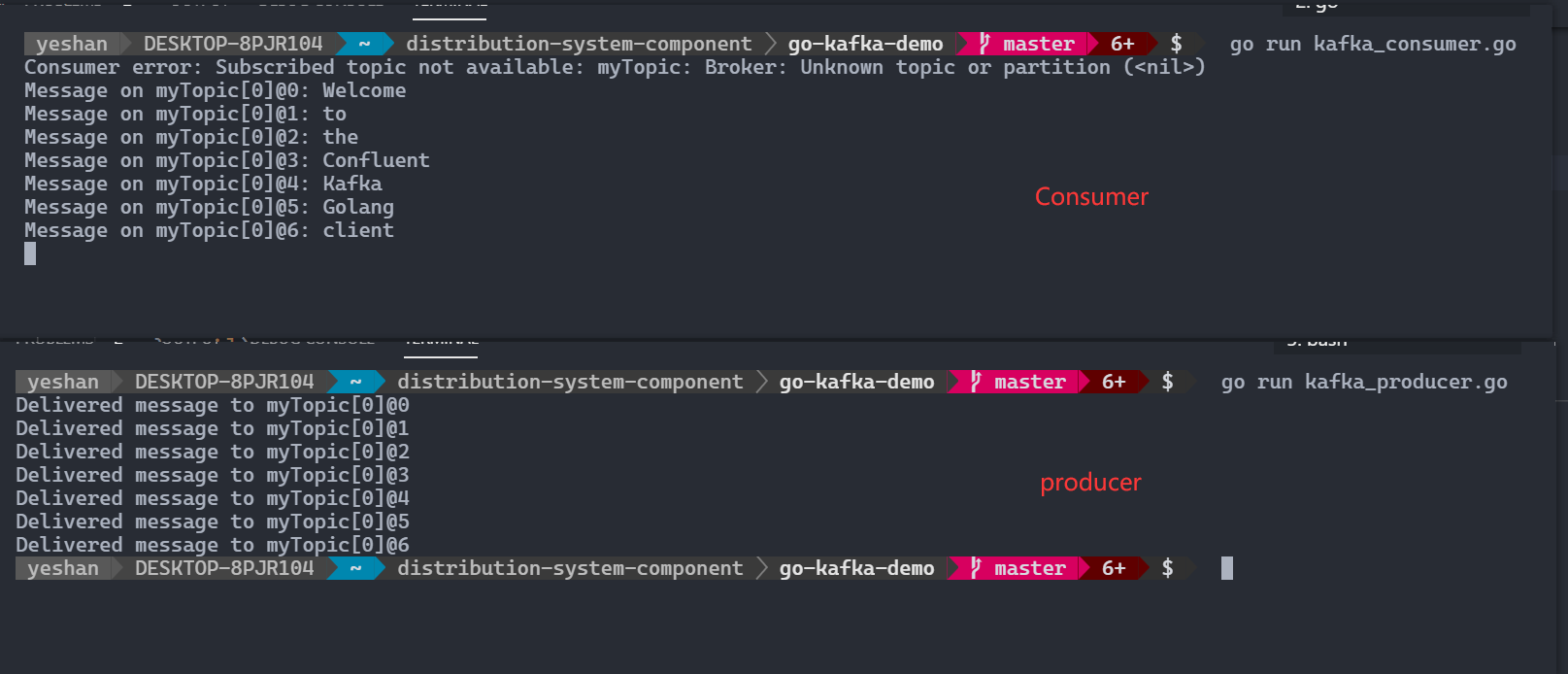
4、两个 terminal,先跑 Consumer,再跑 Producer。
1 2 3 4 # terminal 1 go run kafka_consumer.go # ternimal 2 go run kafka_producer.go
run result
收工,其他东西后续慢慢啃。本文源文件:https://github.com/yeshan333/go-kafka-demo
参考