




使用 GitHub Copilot Agent 创建新的 RSSHub 路由



在 Visual Studio Code 与微信开发者工具中调试使用 emscripten 基于 C 生成的 WASM 代码
在 Visual Studio Code 与微信开发者工具中调试 emscripten 生成的 WASM 代码

(Amazing!) 通过 vfox 在 Windows 上安装管理多个 Erlang/OTP 和 Elixir 的版本
通过 vfox 安装在 Windows 上管理多个 Erlang/OTP 和 Elixir 的版本

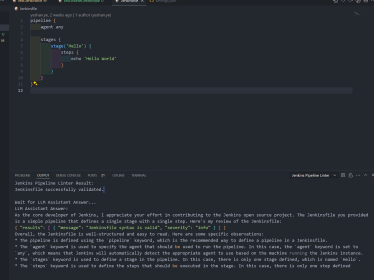
使用 vscode 插件 vscode-jenkins-pipeline-linter-connector 和 LLMs 大模型校验你的 Jenkinsfile
使用 vscode 插件 vscode-jenkins-pipeline-linter-connector 和 LLMs 校验你的 Jenkinsfile


1 / 17