Elixir Macros 系列文章译文
- [1] (译) Understanding Elixir Macros, Part 1 Basics
- [2] (译) Understanding Elixir Macros, Part 2 - Macro Theory
- [3] (译) Understanding Elixir Macros, Part 3 - Getting into the AST
- [4] (译) Understanding Elixir Macros, Part 4 - Diving Deeper
- [5] (译) Understanding Elixir Macros, Part 5 - Reshaping the AST
- [6] (译) Understanding Elixir Macros, Part 6 - In-place Code Generation
原文 GitHub 仓库, 作者: Saša Jurić.
这是讨论 Elixir 宏 (Macros) 系列文章的第一篇. 我原本计划在我即将出版的《Elixir in Action》一书中讨论这个主题, 但最终决定不这么做, 因为这个主题不符合这本书的主题, 这本书更关注底层 VM 和 OTP 的关键部分.
就我个人而言, 我觉得宏的主题非常有趣, 在本系列文章中, 我将试图解释它们是如何工作的, 提供一些关于如何编写宏的基本技巧和建议. 虽然我确信编写宏不是很难, 但与普通的 Elixir 代码相比, 它确实需要更高视角的关注. 因此, 我认为这了解 Elixir 编译器的一些内部细节是非常有帮助的. 了解事情在幕后是如何运行之后, 就可以更容易地理解元编程代码.
这是篇中级水平的文章. 如果你很熟悉 Elixir 和 Erlang, 但对宏还感觉到困惑, 那么这些内容很适合你. 如果你刚开始接触 Elixir 和 Erlang, 那么最好从其它地方开始. 比如 Getting started guide, 或者一些可靠的书.
元编程 (Meta-programming)
或许你已经对 Elixir 中的元编程有一点了解. 其主要的思想就是我们可以编写一些代码, 它们会根据某些输入来生成代码.
正因为有了宏 (Macros), 我们可以写出如下这段来自于 Plug 的代码:
1 | get "/hello" do |
或者是来自 ExActor 的
1 | defmodule SumServer do |
在以上两个例子中, 我们使用到了一些自定义的宏, 这些宏会在编译时 (compile time) 都转化成其它的代码. 调用 Plug 的 get 和 match 会创建一个函数, 而 ExActor 的 defcall 会生成两个函数和将参数正确从客户端进程传播给服务端进程的代码.
Elixir 本身的实现上就非常多地用到了宏. 例如 defmodule, def, if, unless, 甚至 defmacro 都是宏. 这使得语言的核心能保持最小化, 日后对语言的扩展就会更加简单.
鲜为人知的是, 宏可以让我们可以有动态 (on the fly) 生成函数的可能性:
1 | defmodule Fsm do |
在这里, 我们定义了一个 Fsm module, 同样的, 它在编译时会转换成对应的多子句函数 (multi-clause functions).
类似的技术被 Elixir 用于生成 String.Unicode 模块. 本质上讲, 这个模块是通过读取 UnicodeData.txt 和SpecialCasing.txt 文件里对码位 (codepoints) 的描述来生成的. 基于文件中的数据, 各种函数 (例如 upcase, downcase) 会被生成.
无论是宏还是代码生成, 我们都在编译的过程中对抽象语法树做了某些变换. 为了理解它是如何工作的, 你需要学习一点Elixir 编译过程和 AST 的知识.
编译过程 (Compilation process)
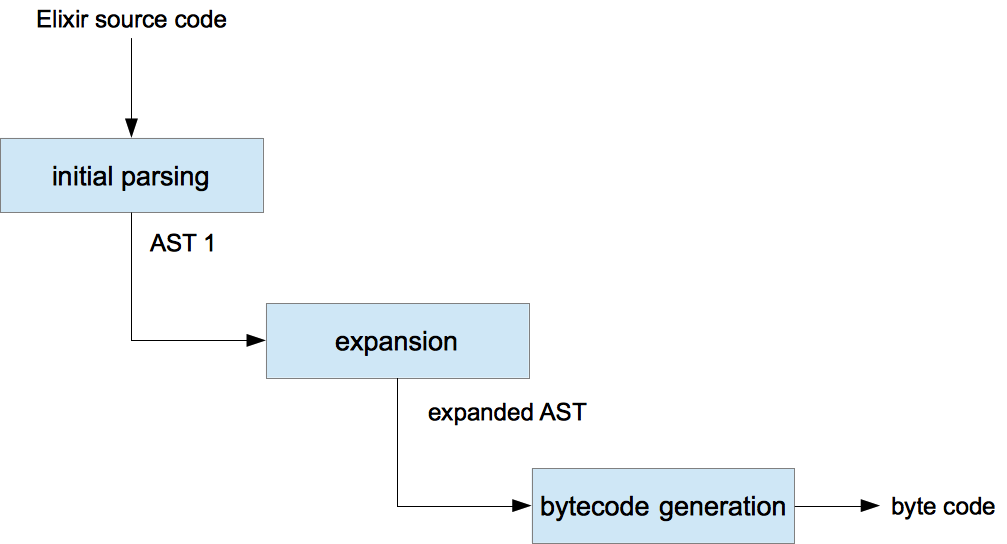
输入的源代码被解析, 然后生成相应的抽象语法树 (AST1). AST1 会以嵌套的 Elixir Terms 的形式来表述你的代码. 然后进入展开阶段. 在这个阶段, 各种内置的和自定义的宏被转换成了最终版本. 一旦转换结束, Elixir 就可以生成最后的字节码, 即源程序的二进制表示.
这只是对整个编译过程的概述. 例如, Elixir 编译器还会生成 Erlang AST, 然后依赖 Erlang 函数将其转换为字节码, 但是我们还不需要知道这部分细节. 不过, 我认为这幅图对于理解元编程代码是有帮助的.
理解元编程魔法的关键点在于理解在展开阶段 (expansion phase) 发生了什么. 编译器会基于原始 Elixir 代码的 AST 展开为最终版本.
另外, 从这个图中可以得到另一个重要结论, Elixir 在生成了二进制之后, 元编程就停止了. 你可以确定你的代码不会被重新定义, 除非使用到了代码升级或是一些动态的代码插入技术 (这不在本文讨论范围). 元编程总是会引入一个隐形 (或不明显)的层, 在 Elixir 中这只发生在编译时, 并独立于程序的各种执行路径.
代码转换发生在编译时, 因此推导最终产品会相对简单, 而且元编程不会干扰例如 dialyzer 这样的静态分析工具. 编译时元编程 (Compile time meta-programming)也意味着我们不会有性能损失. 进入运行时 (run-time) 后, 代码就已经定型了, 代码中不会有元编程结构在运行.
创建 AST 片段
什么是 Elixir AST? 它是一个 Elixir Term (译注: Elixir 中的所有数据都可以看成是 term), 一个深度嵌套的层次结构, 用于表述一个语法正确的 Elixir 代码. 为了说得更明白一些, 举个例子. 要生成某段代码的 AST, 可以使用 quote:
1 | iex(1)> quoted = quote do 1 + 2 end |
使用 quote 可以获取任意一个复杂的 Elixir 表达式对应的 AST 片段.
在上面的例子中, 生成的 AST 片段用于描述一个简单的求和操作 (1+2). 这通常被称为 quoted expression. 大多数时候你不需要去理解 quoted 结构的具体细节, 让我们来看一个简单的例子. 在这种情况下, AST 片段是一个包含如下元素的三元组 (triplet):
- 一个原子 (atom) 表示所要进行的操作 (
:+) - 表达式上下文 (context, 例如 imports 和 aliases). 通常你并不需要理解这个数据
- 操作参数
要点: 这个 quoted expression 是一个描述代码的 Elixir term. 编译器会使用它生成最终的字节码.
虽然不常见, 但对一个 quoted expression 求值也是可以的:
1 | iex(2)> Code.eval_quoted(quoted) |
返回的元组中包含了表达式的结果, 以及一个列表, 其中包含了构成表达式的变量.
但是, 在 AST 被求值前 (通常由编译器完成), quoted expression 并没有进行语义上的验证. 例如, 当我们书写如下表达式时:
1 | iex(3)> a + b |
我们会得到错误, 因为这里没有叫做一个叫做 a 的变量 (或函数).
相比而言, 如果 quote 这个表达式:
1 | iex(3)> quote do a + b end |
这个没有发生错误, 我们有了一个表达式 a+b 的 quoted 表现形式. 其意思是, 生成了一个描述该表达式 a+b 的 term, 不管表达式中的变量是否存在. 最终的代码并没有生成, 所以这里不会有错误抛出.
如果把该表述插入到某些 a 和 b 是有效标识符的 AST 中, 刚才发生错误的代码 a+b, 才是正确的. 下面来试一下, 首先 quote 一个求和 (sum)表达式:
1 | iex(4)> sum_expr = quote do a + b end |
然后创建一个 quoted 变量绑定表达式:
1 | iex(5)> bind_expr = quote do |
记住, 它们只是 quoted 表达式. 它们只是在描述代码的简单数据, 并没有执行. 这时, 变量 a 和 b 并不存在于当前 Elixir shell 会话 (session)中.
要使这些片段能够一起工作, 必须把它们连接起来:
1 | iex(6)> final_expr = quote do |
这里我们生成了一个由 bind_expr 和 sum_expr 构成的新的 quoted expression -> final_expr. 实际上, 我们生成了一个新的 AST 片段, 它结合了这两个表达式. 暂不要关心 unquote 的部分 - 我稍后会解释这一点.
与此同时, 我们可以进行求值计算这个 AST 片段 (fragment):
1 | iex(7)> Code.eval_quoted(final_expr) |
再次看到, 求值结果由一个表达式结果 (3), 一个变量绑定列表构成. 形如:
1 | {expression, [{{:variable, Elixir}, value},...]} |
从这个绑定列表中我们可以看出, 该表达式绑定了两个变量 a 和 b, 对应的值分别为 1 和 2.
这就是在 Elixir 中元编程方法的核心. 当我们进行元编程的时候, 我们实际上是把各种 AST 片段组合起来生成新的我们需要的 AST. 我们通常对输入 AST 的内容和结构不感兴趣, 相反, 我们使用 quote 生成和组合输入片段, 并生成经过修饰后的代码.
Unquoting
unquote 在这里出现了. 注意, 无论 quote 块 (quote ... end) 里有什么, 它都会变成 AST 片段. 这意味着我们不可以简单地将外部的变量注入到我们的 quote 里. 例如, 这样是不能达到效果的:
1 | iex(8)> quote do |
在这个例子中, quote 仅仅是简单的生成对 bind_expr 和 sum_expr 的变量引用, 它们必须存在于这个 AST 可以被理解的上下文环境里. 但这不是我们想要的结果. 我需要的效果是有一种方式能够直接注入 bind_expr 和 sum_expr 的内容到生成的 AST 的对应的位置.
这就是 unquote(...) 的目的 - 括号里的表达式会被立刻执行, 然后就地插入到调用了 unquote 的地方. 这意味着 unquote 的结果必须是合法的 AST 片段.
理解 unquote 的另一种方式是, 可以把它看做是字符串的插值 (#{}). 对于字符串你可以这样写:
1 | "....#{some_expression}...." |
类似的, 对于 quote 可以这样写:
1 | quote do |
对此两种情况, 求值的表达式必须在当前上下文中是有效的, 并注入该结果到你构建的表达式中. (要么是 string, 或者是一个 AST 片段)
理解这一点很重要: unquote 并不是 quote 的反向过程. quote 将一段代码转换成 quoted 表达式 (quoted expression), unquote并没有做逆向操作. 如果需要把一个 quoted expression 转换为字符串, 可以使用 Macro.to_string/1.
1 | iex(9)> Macro.to_string(bind_expr) |
例子: tracing expression
理论结合实践, 一个简单例子, 我们将编写一个帮助我们调试代码的宏. 这个宏可以这样用:
1 | iex(1)> Tracer.trace(1 + 2) |
Tracer.trace 接受一个给定的表达式, 会打印其结果到屏幕上. 然后返回表达式的结果.
需要认识到这是一个宏, 它的输入(1+2)可以被转换成更复杂的形式 — 打印表达式的结果并返回它. 这个变换会发生在宏展开阶段, 产生的字节码为输入代码经过修饰的版本.
在查看它的实现之前, 想象一下最终的结果或许会很有帮助. 当我们调用 Tracer.trace(1+2), 对应产生的字节码类似于这样:
1 | mangled_result = 1 + 2 |
mangled_result 表示 Elixir 编译器会销毁所有在宏里引用的临时变量. 这也被称为宏清洗 (macro hygiene), 让宏保持干净, 不会影响到使用宏的代码, 我们会在本系列之后的内容中讨论它(不在本文).
该宏的定义是这样的:
1 | defmodule Tracer do |
让我们来逐步分析这段代码.
首先, 我们用 defmacro 定义宏. 宏本质上是特殊形式的函数. 它的名字会被销毁, 并且只能在展开期调用它(尽管理论上你仍然可以在运行时调用).
我们的宏接收到了一个 quoted expression. 这一点非常重要 — 无论你发送了什么参数给一个宏, 它们都已经是 quoted 的. 所以, 当我们调用 Tracer.trace(1+2), 我们的宏(它是一个函数)不会接收到 3. 相反, expression_ast 的内容会是 quote(do: 1+2) 的结果.
在第三行, 我们使用 Macro.to_string/1 来求出我们所收到的 AST 片段的字符串表达形式. 这是你在运行时不能够对一个普通函数做的事之一. 虽然我们能在运行时调用 Macro.to_string/1, 但问题在于我们没办法再访问 AST 了, 因此不能够知道某些表达式的字符串形式了.
一旦我们拥有了字符串形式, 我们就可以生成并返回结果 AST 了, 这一步是在 quote do ... end 结构中完成的. 它的结果是用来替代原始的 Tracer.trace(...) 调用的 quoted expression.
让我们进一步观察这一部分:
如果你明白 unquote 的作用, 那么这个就很简单了. 实际上, 我们是在把 expression_ast(quoted 1+2)代入到我们生成的片段(fragment)中, 将表达式的结果放入 result 变量. 然后我们使用某种格式来打印它们(借助 Macro.to_string/1), 最后返回结果.
展开一个 AST
在 Shell 观察其是如何连接起来是很容易的. 启动 iex Shell, 复制粘贴上面定义的 Tracer 模块:
1 | iex(1)> defmodule Tracer do |
然后, 必须 require Tracer:
1 | iex(2)> require Tracer |
接下来, 对 trace 宏调用进行 quote 操作:
1 | iex(3)> quoted = quote do Tracer.trace(1+2) end |
现在, 输出看起来有点恐怖, 通常你不必需要理解它. 但是如果你仔细看, 在这个结构中你可以看到 Tracer 和 trace, 这证明了 AST 片段是何与源代码相对应的, 但还未展开.
现在, 该开始展开这个 AST 了, 使用 Macro.expand/2:
1 | iex(4)> expanded = Macro.expand(quoted, __ENV__) |
这是我们的代码完全展开后的版本, 你可以看到其中提到了 result(由宏引入的临时变量), 以及对 Tracer.print/2 的调用. 你甚至可以将这个表达式转换成字符串:
1 | iex(5)> Macro.to_string(expanded) |
这些说明了你对宏的调用已经展开成了别的东西. 这就是宏工作的原理. 尽管我们只是在 shell 中尝试, 但使用 mix 或elixirc 构建项目时也是一样的.
我想这些内容对于第一篇来说已经够了. 你已经对编译过程和 AST 有所了解, 也看过了一个简单的宏的例子. 在下一篇 《(译) Understanding Elixir Macros, Part 2 - Micro Theory》, 我们将更深入地讨论宏的一些机制.
译注
- codepoints: 通常是一个数字, 用于表示 Unicode 字符.
- Terms: 任何数据类型中的一段数据都被称为 term.



