



Python多进程&&多线程(初步)
进程 && 线程
进程:进程是操作系统中执行的一个程序,操作系统以进程为单位分配存储空间,每个进程都有自己的地址空间、数据栈以及其他用于跟踪进程执行的辅助数据,操作系统管理所有进程的执行,为它们合理的分配资源。进程可以通过fork或者wpawn的方式来创建新的进程执行其他任务,不过新的进程有自己独立的内存空间和数据栈,所以必须通过进程间的通信机制(IPC,Inter Process Communication)来实现数据共享,具体的方式包括管道、信号、套接字、共享内存等。
线程:进程的一个执行单元。线程在同一个进程中执行,共享程序的上下文。一个进程中的各个线程与主线程共享同一片数据空间,因而相比与独立的进程,线程间的信息共享和通信更为容易。线程一般是以并发的方式执行的。注意在单核CPU系统中,真正的并发是不可能的,所以新城的执行实际上是这样规划的:每个线程执行一小会,然后让步给其他线程的任务(再次排队等候更多的CPU执行时间)。在整个线程的执行过程中,每个线程执行它自己的特定的任务,在必要时和其他进程进行结果通信。
Python多进程(使用multiprocessing)
1 | from time import time, sleep |
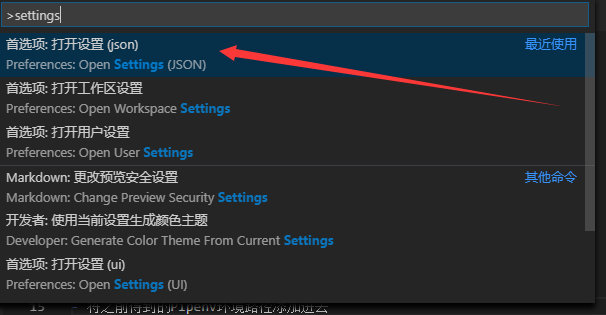
vscode配置Pipenv工作环境

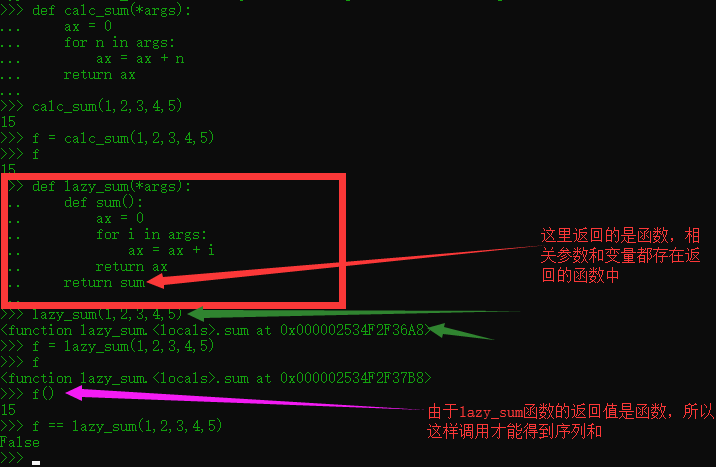
python生成器回顾

浅尝BeautifulSoup
1 | import requests |